让 Agent 变成 “大模型供应商”
目前,AgentRun 快速创建的 Agent 以及 AgentRun SDK 的 AgentServer 已经支持了 OpenAI Chat Completions、AG-UI 协议。 其中 OpenAI Chat Completions 是广泛使用的大模型调用协议,通过该协议,您可以像调用大模型一样使用您的 Agent。
- 集成速度: 将 Agent 封装为“模型”后可快速在 Open WebUI、Cherry Studio 等平台注册并使用,显著缩短集成时间。
- 能力内置化: 可把高级能力(访问内部 API、专用工具)作为模型能力内置,调用方无需重复实现。
- 上层系统简化: 外部系统只需调用统一模型接口,减少业务方的复杂度与维护成本。
- 复用与共享: 团队或生态内可共享同一“增强模型”,降低重复开发、促进能力沉淀。
尽管 AgentRun 已经支持了通过 OpenAI Chat Completions 调用,但如果您进行详细的测试,会发现我们只处理了 stream 和 messages 字段。
这是因为 Agent 和大模型的使用场景不完全一致,Agent 交付的是一个经过详细调整,具备特定功能的整体。、
以 AgentRun 探索页面的 “码呀码” 为例,这是一个可以帮助您撰写代码的模板,模板作者选择了 qwen3-coder 作为开发模型,并且通过大量测试找到了与系统提示词相匹配的模型参数。如果允许用户随意修改,则很可能会导致生成的代码完全无法使用。
对于大部分场景,我们并不建议您允许您的客户随意进行调整。但如果您的场景可以放开参数限制,那么只需要进行简单的调整即可将您的 Agent 变成真正的 “大模型供应商”
将快速创建 Agent 改造为 “大模型供应商”
以快速创建的 Agent 为例,首先在 AgentRun 控制台 - Agent 运行时 快速创建一个 Agent
Agent 配置可以根据您的实际需要进行调整。
创建完成后,将 Agent 转换为高代码的 Agent,此时您就可以根据实际需要随意调整 Agent 的实现了。
借助 WebIDE,您可以快速进行代码的修改。
参考如下的方式,改造您的代码,即可通过 OpenAI Chat Completions 的 model 字段指定实际调用的模型。
# 如果 system_prompt_vars 非空,则展开 system_prompt
if system_prompt_vars:
system_prompt = expand_prompt_from_vars(system_prompt, system_prompt_vars)
logger.info(f"Expanded system_prompt with variables: {system_prompt_vars}, system_prompt: {system_prompt}")
body = await request.raw_request.json()
body_model = body.get("model", "")
logger.info(f"model from body: {body_model}")
current_agent = create_agent(
system_prompt=system_prompt, # 使用环境变量中的 PROMPT
model_name=model_name,
model_name=body_model or model_name,
api_key=api_key,
base_url=base_url,
model_parameter_rules=model_parameter_rules
)
# 获取 thread_id(从 header 或生成一个)
# 注意:HTTP header 名称在传递时可能会被转换为小写,所以同时检查大小写
thread_id = (
raw_headers.get('X-AgentRun-Session-ID') or
raw_headers.get('x-agentrun-session-id') or
raw_headers.get('X-Agentrun-Session-Id') or
f"agentrun-{os.urandom(8).hex()}"
)
此时,您在调用时便可以随意调整模型的名称,可以参考的调用方式如下
curl https://xxxxxx/Default/invocations/openai/v1/chat/completions -XPOST \
-H "content-type: application/json" \
-d '{
"model": "deepseek-v3",
"messages": [{"role": "user", "content": "你是什么模型?"}],
"stream":true
}'
除去使用客户端传入的 model 外,您还可以
- 识别
temperature等参数,控制传入模型的温度 - 对模型进行映射,在您的客户传入
my-model-lite调用qwen-flash,在传入my-model-pro调用qwen3-max - 改造传入框架的 model 字段,实现大模型的聚合能力。根据传入的模型名自动选择不同的模型平台
- 识别客户端的工具,实现客户端工具调用
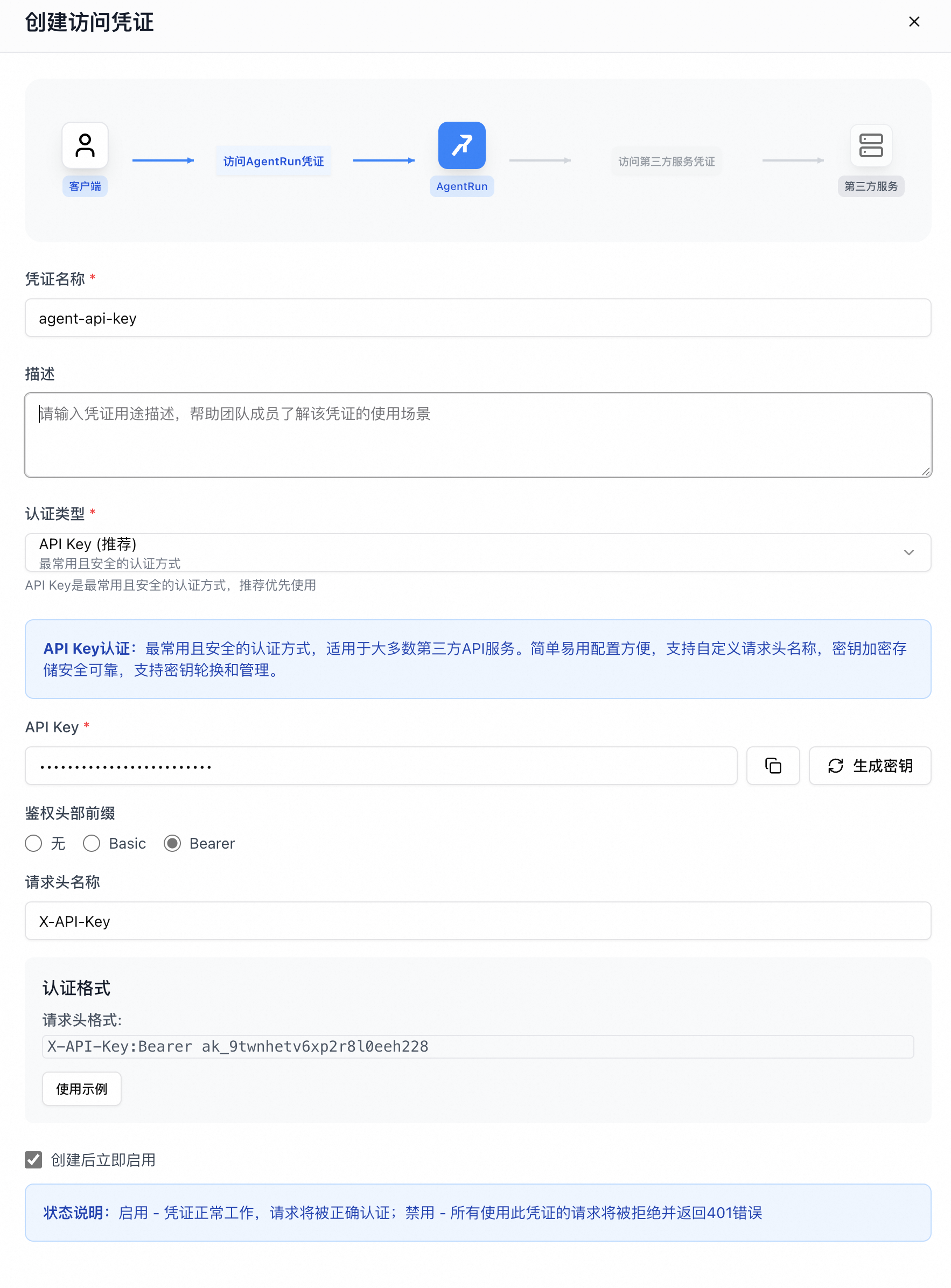
让您的 Agent 也支持 API KEY 鉴权
大模型的鉴权通常使用 API KEY 进行鉴权,需要客户端在头部传入 Authorization: Bearer sk-12345。
为了安全起见,我们也可以为我们的 Agent 配置 API KEY,在 Agent 编辑页面,配置 Agent 凭证
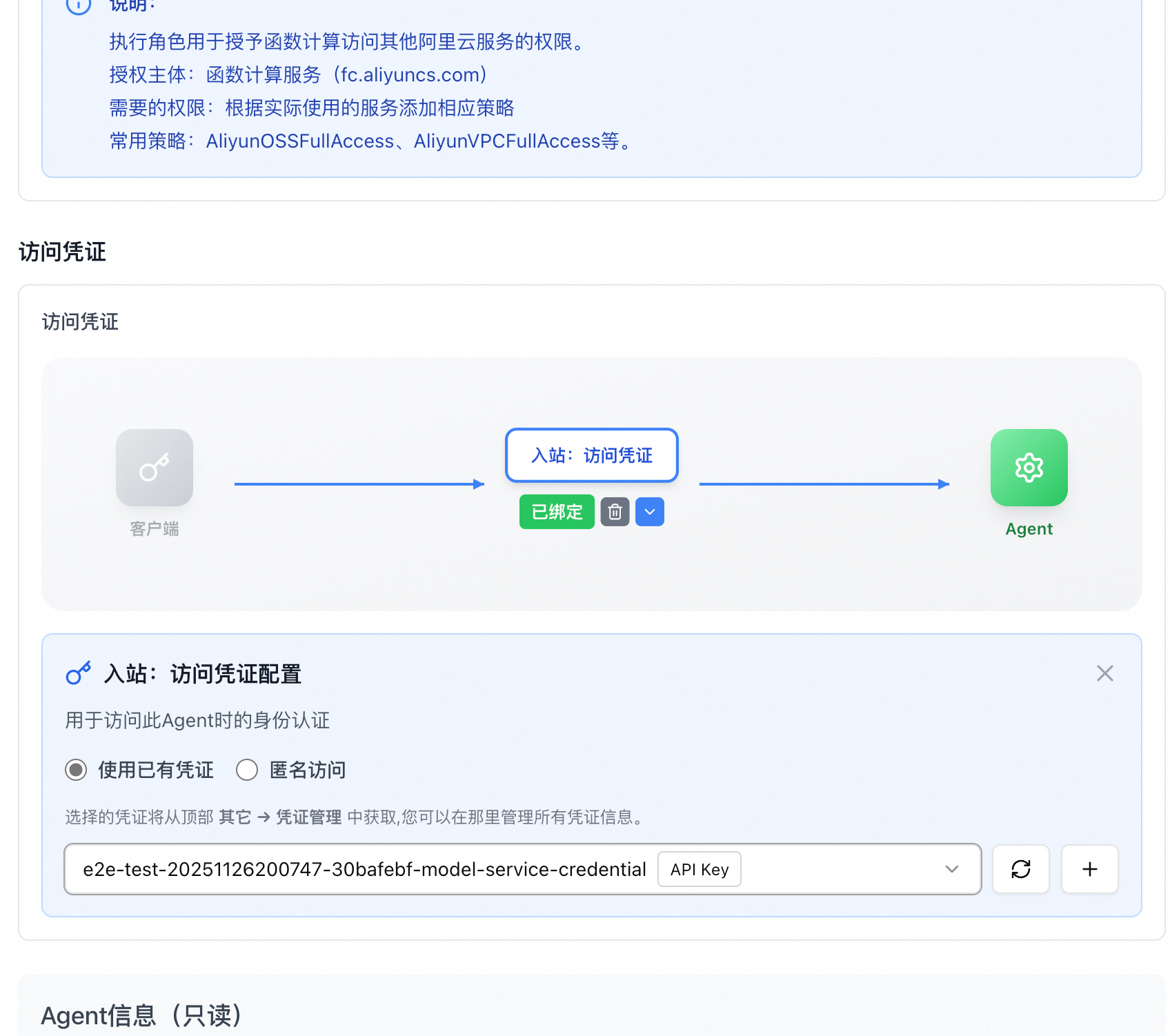
在入站凭证选择 API KEY 模式,鉴权头部前缀选择 Bearer
此时,客户端再次调用就必须携带 Authorization 头部了。通常,您只需要将不包含 Bearer 的部分传入客户端的 API KEY 的配置即可
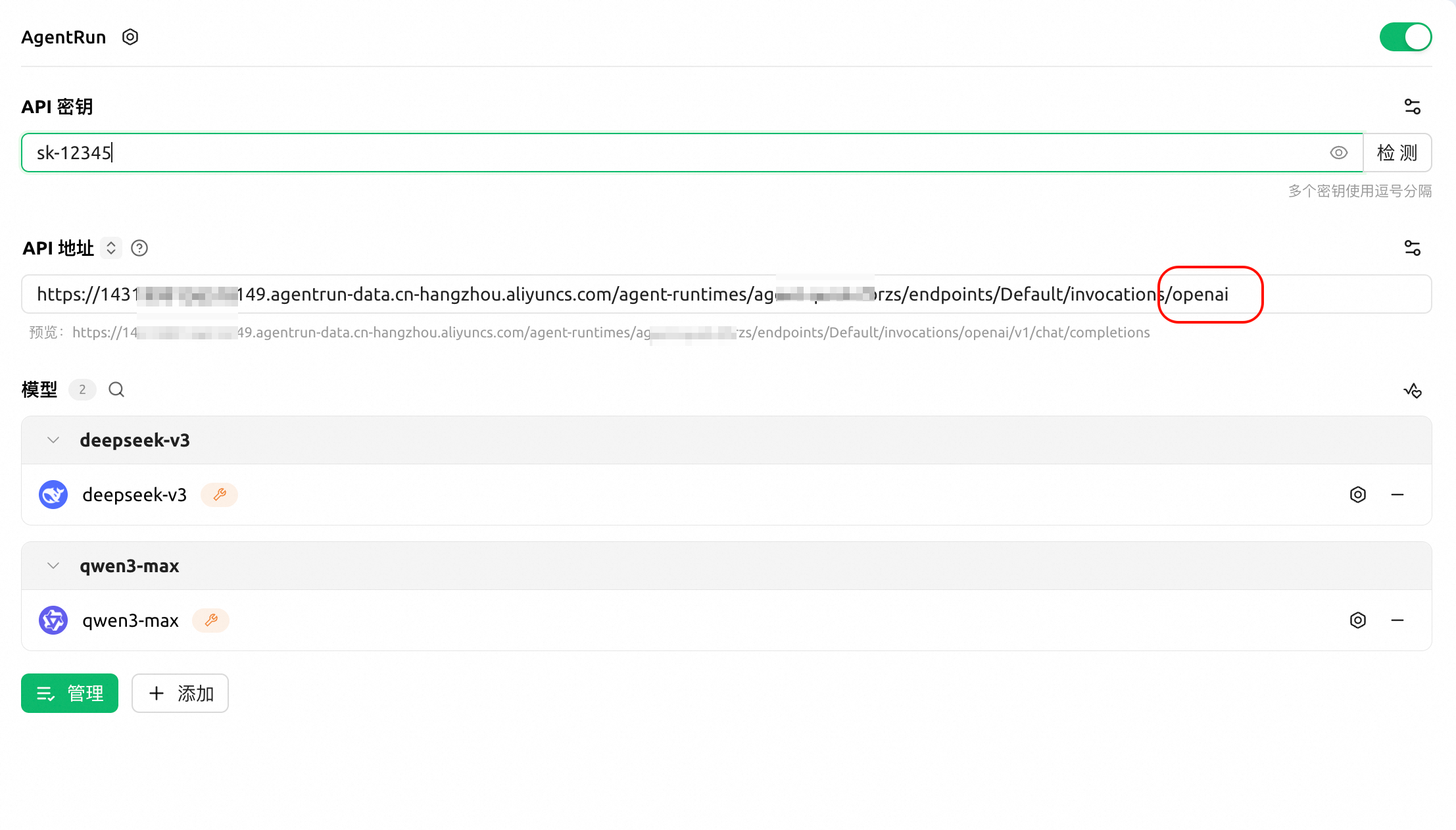
在 Cherry Studio 使用
以 Cherry Studio 为例,您可以在任意其他平台以类似的方式进行配置
通常需要的配置内容如下(如果可以选择的话,请选择 OpenAI Chat Completions 协议,而非 OpenAI Responses 协议)
- Base URL: 在您的 Agent 访问地址(通常为
xxxxx/invocations)或您绑定的自定义域名后,增加/openai - API KEY: 您的 Agent 凭证内容(不包含
Bearer部分) - 模型: 与您的 Agent 实际逻辑相关
- 如果您按照上述的方式改造,则可以填入您选择的 AgentRun ModelService 配置的所有模型
- 如果您增加了模型名称映射能力,则可以填入您的映射模型名称
下面是分别调用不同模型的结果

